The DeepSeek R1 model, developed by a team from China, has made waves in the AI world. It has surpassed ChatGPT and climbed to the top spot on the US App Store. Furthermore, DeepSeek has shaken the US tech stock market with its innovative R1 model, which claims to rival ChatGPT o1. Although you can access DeepSeek R1 for free on its official website, many users are concerned about privacy since the data is stored in China. If you’d like to run DeepSeek R1 on your PC or Mac, you can easily do so using LM Studio and Ollama. Here’s a step-by-step guide to help you get started.
What is Needed to Run DeepSeek Locally?
To operate DeepSeek R1 on a PC, Mac, or Linux system, your machine should have a minimum of 8GB of RAM. This amount of memory allows you to smoothly run the small DeepSeek R1 1.5B model, providing output at approximately 13 tokens per second. You can also handle the 7B model, but it will utilize around 4GB of memory, potentially causing your system to be a bit sluggish.
With additional memory, you could also manage the 14B, 32B, and 70B models, although a faster CPU and GPU would be necessary. Currently, most software doesn’t leverage the NPU (Neural Processing Unit) for running local AI models. Instead, they primarily depend on the CPU and, in certain instances (such as high-end Nvidia GPUs), the GPU is used for inferencing.
For Android phones and iPhones, it’s advisable to have at least 6GB of memory to efficiently run the DeepSeek R1 model locally. You can operate DeepSeek R1 on your Snapdragon 8 Elite, or other Snapdragon chipsets in the 8-series and 7-series. Moreover, you can explore how the Deepseek R1 and ChatGPT o1 models stack up right here.
Run DeepSeek R1 on PC Using LM Studio or Olama
LM Studio and Ollama are both tools designed to help developers and researchers work with large language models (LLMs) locally on their machines. LM Studio is a desktop application that allows users to discover, download, and run open-source LLMs locally on their computers. Ideal for users who want to explore different LLMs without needing to set up complex environments.
[optional Making LM Studio Portable]
The offiial website doesnt provide portable version however a github repo make it portable. Steps are:
- Doenload LM Studio Portable Launch Script (LMS PLS)
-
Unzip it. It will look like this:
- Downlod LM-Studio installer from website and put in installer Folder.
- Execute launchLMS.cmd with admin right
- LM Studio will install inside App folder
- Here, under Model Search, you will find the “DeepSeek R1 Distill (Qwen 7B)” model
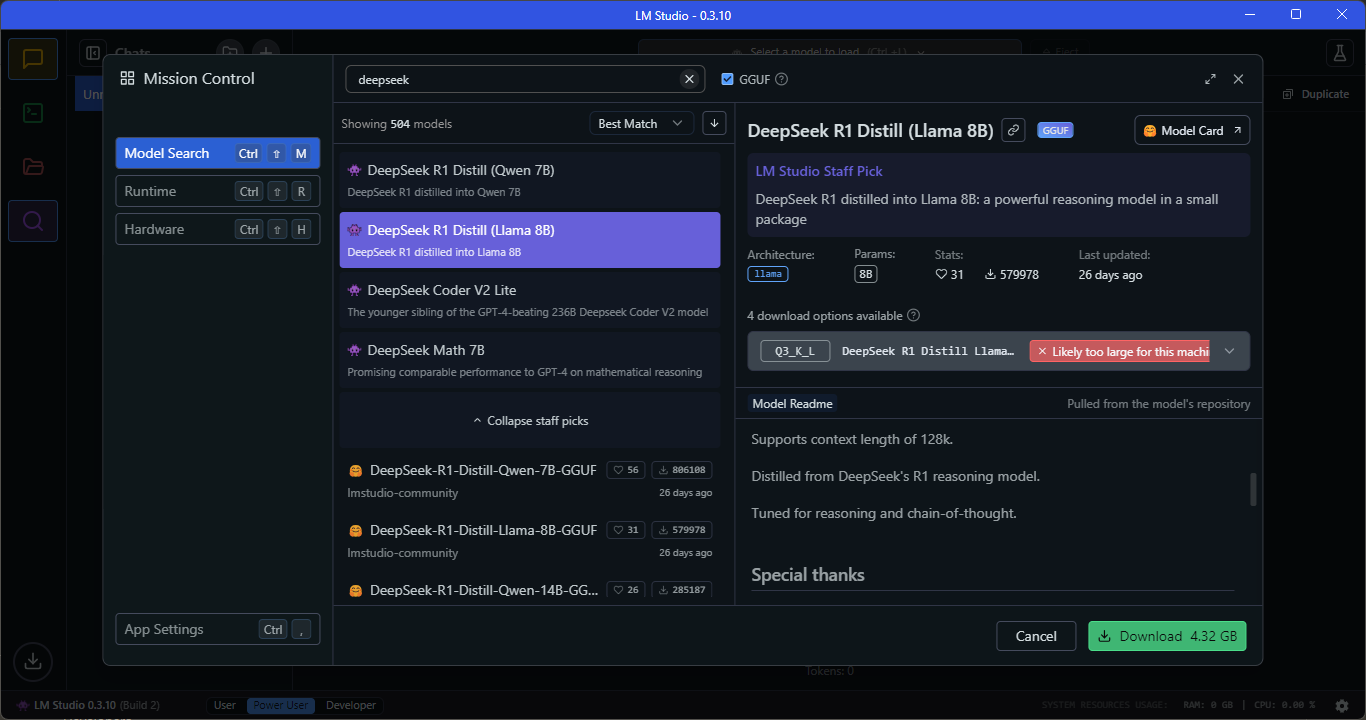
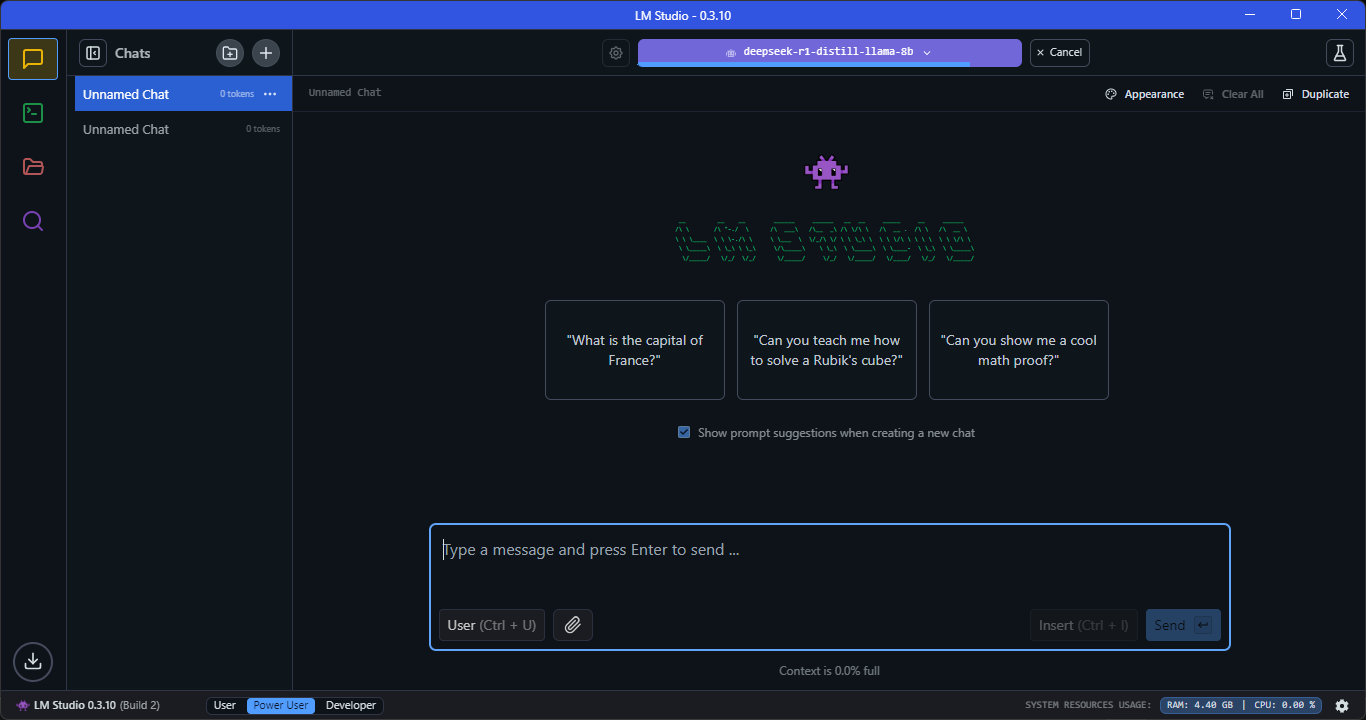
- Once the DeepSeek R1 model is downloaded, switch to the “Chat” window and load the model.
Running Large Models Efficiently
The type of GPU you need depends on the model size and optimizations:
-4GB VRAM – Small models (e.g., Mistral 7B with heavy quantization like 4-bit GGUF).
-8GB VRAM – Mid-sized models (e.g., LLaMA 2 7B, Mistral 7B with moderate quantization).
-12GB VRAM – Can run 7B models at full precision or 13B models with quantization.
-16GB VRAM – Good for 13B models without quantization or 30B models with offloading.
-24GB+ VRAM (e.g., RTX 4090, A6000) – Can run 30B models comfortably and even 65B models with optimizations.
-Multi-GPU setups (e.g., Dual RTX 3090s, A100s, H100s) – Required for 65B+ models at full precision.
For those with lower VRAM, techniques like CPU offloading, quantization (GGUF, GPTQ, AWQ), and tensor parallelism can help run larger models.
Optimizing for Performance
Since LLMs are memory-intensive, consider these optimizations:
-Use Quantized Models (GGUF, GPTQ, AWQ, etc.) – Reduce VRAM usage while maintaining good quality.
-Use Flash Attention & LoRA Fine-Tuning – Improves inference speed and reduces memory usage.
-Enable CUDA Acceleration – Ensures the RTX 4090 is utilized for faster inference (--use-cuda in llama.cpp).